※この記事は備忘に近いので、今後テストの度にこのページを改訂していく可能性があります。
QA Heatmap Analyticsは膨大なデータを処理することを想定しているので、仮に月間1000万PV近いサイトを分析する場合、1億件以上のデータを処理しなくてはなりません。
この処理に時間がかかるようでは、実用的ではなく、どのようなクライアントスペックが必要なのか、またどのくらい速度がかかるのかを簡単に検証したいと思いました。
そこで、シンプルなテストで、まずはChromeブラウザがどれくらいの速度で1億件のデータを処理するのかを計測してみました。
検証方法
Chromeを使用し、ある程度QA Heatmap で実際に想定している配列データ(ほとんどInt型で構成。一部文字列。通常DBであれば1レコード最低70Byte程度は必要)を1億件構築し、簡単なテキスト検索を行ってみました。詳しくはテストコードをご覧ください。
特に検証したかったこと。
- 1億件の配列の作成にどれくらい時間がかかるか
- 全てオンメモリするのか
- ループの書き方でどのくらい速度の違いがあるか?
検証環境
- iMac OS macOS Big Sur
- CPU 3.4GHz クアッドコア Intel Core i5
- メモリ 40GB
- ディスク HDD(ただしフュージョンドライブなので一部SSD)
- Chrome バージョン: 87.0.4280.67(Official Build) (x86_64)
- メモリ利用量の確認方法
- Chromeタスクマネージャーでタブに割り当てられたメモリを確認
結果
速度について
| 作業 | 方法 | 速度 |
| 1億件の配列作成 | forループ | 5609ms |
| 作成直後に文字列検索 | forループ | 3964ms |
| forEachメソッド | ※1回目メモリーリーク発生 5296ms |
速いのはforループです。また5秒程度で1億件処理するのは、結構速いな、と思いました。しかしそれより問題なのは後述するメモリーリークです。
メモリ利用量について
| フェーズ | メモリ量 |
| 配列作成前 | 18.4MB |
| 作成後 | 2.6GB |
| 10分ブラウザ放置後 | 1.9GB |
普通に計算すれば1億件で700MB程度は最低必須のデータです。こちらをforループで配列作成したところ、ある意味想定通り、数GBのメモリを確保しオンメモリしました。
あと面白いのは、ブラウザを放置するとメモリ確保量が減っています。ヒープで余分に確保していたメモリなどを最適化できるのだと考えています。しかし今回はその程度のガベージコレクションがあっても、そもそも後述するメモリーリークが大問題なので、どうでもいい話だと思います。
メモリーリークの発生!
一回目のforループが終わったあと、すぐにforEachをかけると、22584ループ目で「Paused before potential out-of-memory crash」が発生しました。いわゆるメモリーリークです。
下記のChromeDevToolの公式サイトを参考に原因の解明を行おうと思ったのですが、、
▼メモリ問題の解決(Chrome DevTools)
https://developers.google.com/web/tools/chrome-devtools/memory-problems/
なにせ1億件もあるとデバッグも大変で、Heapのスナップショットの取得、描画だけでも異様に時間がかかります。下記のように40GBのメモリを積んでいても関係ないくらいメモリを喰い、スワップ発生しまくりです。
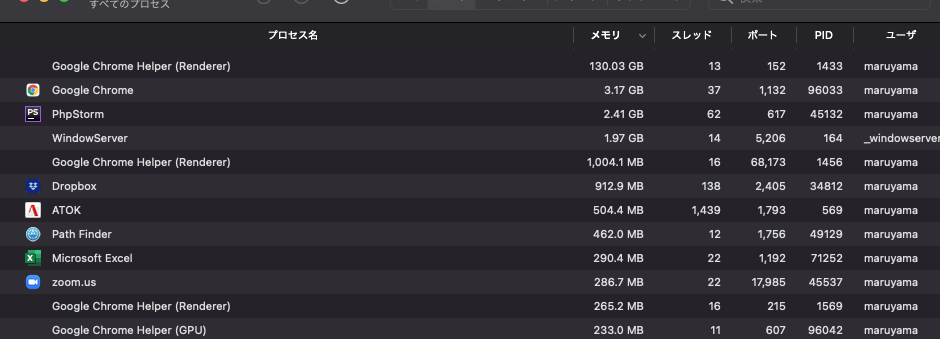
結局、数時間まっても動かず、どちらにせよ、下記のブラウザのメモリ限界に達した可能性が極めて高く、所感にも記載しますが、そもそも数GBのメモリ確保は現実的ではないので原因の追及はやめることにしました。
Chromeのメモリ最大容量は4GBらしい
すごく参考になる検証をされている方がいたので下記にリンクを記載しますが、そもそもChromeのメモリの最大容量は4GBのようです。さらに他のブラウザも検証されていて、Safiriでは1.4GBあたりでクラッシュ。それを考えても数GBのメモリを確保して処理させるのは危険すぎます。
▼ブラウザで扱えるメモリ上限の確認 -nodachisoft
https://nodachisoft.com/common/jp/article/jp000005/
所感
メモリ容量が大きいパソコンを使えば、想定通り1GBを超えてもオンメモリはできました。
しかし、その後が悲惨で、そもそも各ブラウザのメモリの上限が1〜4GBでばらついていることを考えてもメモリリークしないように管理するのは至難の業だと思われます。
結論として、使用するメモリは合計で1GB以内で想定した方がよさそうですし、できるだけ小さくする方が良いでしょう。
そうなると、数億というデータ分析は、BigQueryや、TresureDataなどのCDP、クライアントであればTableauなどの専用ツールに任せるのがベターです。そもそも数億のデータを持ちうる企業でデータ活用の文化がないことは考えづらいので、生データをうまくひけるAPIを整備する方が現実的でしょう。
ちなみにGoogleスプレッドシートの最大処理件数が500万行、Excelで100万行程度らしいので、やはり一億どころか一千万という単位からデータ活用は別次元で考えた方が良さそうです。
なお今回のテストの副産物として、処理速度を見ると、巨大な配列になるほどforEachなど配列メソッドは遅くなりそうなので、なるべく避けていき、forループなど、ネイティブに近そうなシンプルな処理を組み合わせるのがよさそうだと思っています。
過去にSafariのDate.Parse()の遅さ(微妙な差なのですがループが多いと効く)でハマったことがあり、なるべくブラウザ依存しなそうな処理を使い、メモリとCPUを想像しながらプログラムを書くことが求められそうです。
テストコード
<h1>1億件の配列作成</h1>
<input type="button" value="start" onclick="datamake();">
<br>forLoop<input type="text" onchange="findtext(this)">
<br>forEach<input type="text" onchange="findtext2(this)">
<script>
let ary = [];
function datamake() {
let now = new Date();
console.log(now.getTime());
for (let iii = 0; iii < 100000000; iii++) {
ary.push([1, 1, 1, 1, 190, 0, 0, 2, '2020-11-15 13:30:23', 1, 0, 45, 0, 0]);
}
let end = new Date();
console.log(end.getTime());
}
function findtext(obj) {
let findtxt = obj.value;
console.log('for loop');
let now = new Date();
console.log(now.getTime());
let findidx = [];
for (let iii = 0; iii < ary.length; iii++) {
//indexOf が一番早い http://oredon.guitarkouza.net/blog/2017/03/javascript-string-match.php
if (ary[iii][8].indexOf(findtxt) > -1) {
findidx.push(iii);
}
}
let end = new Date();
console.log(end.getTime());
console.log(findidx.length);
}
function findtext2(obj) {
let findtxt = obj.value;
console.log('for Each');
now = new Date();
console.log(now.getTime());
let findidx2 = [];
ary.forEach( (rowary,idx) => {
if (rowary[8].indexOf(findtxt) > -1) {
findidx2.push(idx);
}
});
end = new Date();
console.log(end.getTime());
console.log(findidx2.length);
}
</script>