カテゴリー: ブログ
QuarkAプロダクトの開発者ブログです。開発秘話や日々の取組などをご紹介しています。
-
QAが稼働するWordPressテンプレート一覧
QAアナリティクスは、WordPressの標準的な機能(関数)を活用し、JavaScriptによる計測タグを用いて自動でデータ収集を行います。 その性質上、Wo… →続きを読む
投稿者

-
2022年5月から6月初旬にかけて実施した、QA アナリティクスの機能修正・改善まとめ
QA アナリティクスは5月17日にver3.0にバージョンアップし、大きく生まれ変わりました。大幅に仕様を変更したり機能を追加するバージョンアップだけでなく、Q… →続きを読む
投稿者

-
2022年5月17日、QAは大きく生まれ変わります
2022年5月17日、QAは大きく生まれ変わります。 背景 私たちは「データは意思のあるすべての人が公平に手に入れるべきパワー」であり、「すべての人が観察を楽し… →続きを読む
投稿者
-
QA Heatmap Analyticsの負荷対策やプラグインの競合について
開発の丸山です。こんにちは。 今日は多くの人が気にされる データ容量大丈夫? プラグインの競合は? プラグインは重い?サイトの表示速度は遅くならない? の3つに… →続きを読む
投稿者

-
サイト分析をゲームのように楽しく!QAがバージョン2.0になりました。
先日8月17日、QAヒートマップアナリティクスがメジャーアップデートし、Version2.0になりました。 メニューとして大きく変わったのは、「ホーム」が新設さ… →続きを読む
投稿者
-
QA 1周年記念ありがとうWキャンペーン「Twitterフォロー&RT」コース
\日本から世界へ!観察が楽しくなるアクセス解析WordPressプラグイン/ Twitterフォロー&RTで世界一しあわせな動物クオッカステッカープレゼ… →続きを読む
投稿者

-
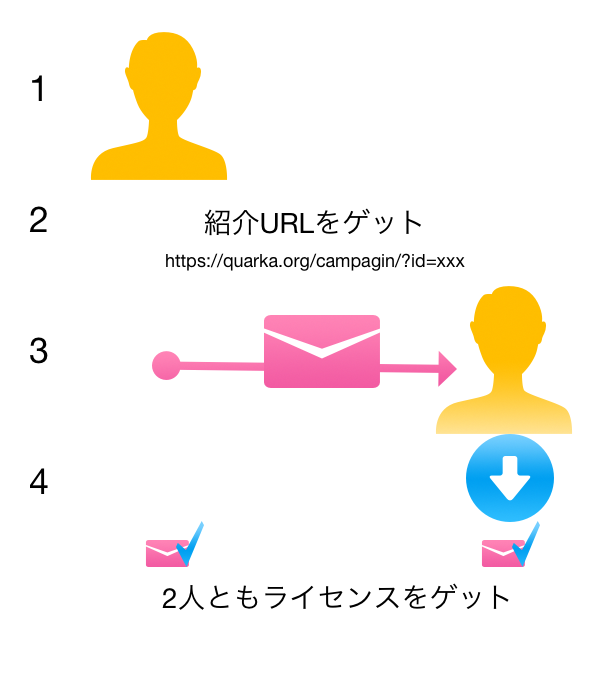
QA 1周年記念ありがとうWキャンペーン「お友達紹介でQAライセンスGet」コース
\日本から世界へ!観察が楽しくなるアクセス解析WordPressプラグイン/ お友達紹介でQAライセンス総額10万円分プレゼント! \全員に当たる!/ お友達を… →続きを読む
投稿者

-
QAは2月12日に一周年を迎えます
QA Heatmapがβ版として本サイト内で産声をあげた2020年2月12日。 それからコロナの本格化など、予想もしていなかった形で世界が大変になり、急速なオン… →続きを読む
投稿者
-
1億件のデータをJavaScriptで処理した時の所要時間
※この記事は備忘に近いので、今後テストの度にこのページを改訂していく可能性があります。 QA Heatmap Analyticsは膨大なデータを処理することを想… →続きを読む
投稿者
-
ExcelみたいなフィルターをJavaScriptで。QAフィルターを作成しました!
2021年8月16日追記。Ver.2.0.0.0より、使い心地はそのままにQAフィルターのデザインが新しく使いやすくなっています。たとえば「どのLPがよく読まれ… →続きを読む
投稿者
-
ウェブサイト分析ソフトウェア開発の舞台裏(後編)
こんにちは。QuarkAの丸山です。 前回はウェブサイト分析ソフトウェアの敵が「インフラコスト」であること、それが故、無料ヒートマップツールの実現が困難であった… →続きを読む
投稿者
-
ウェブサイト分析ソフトウェア開発の舞台裏(前編)
こんにちは。QuarkAの丸山です。 QA Heatmap Analyticsは、もうすぐVer.0.9の録画再生機能がリリースされる予定です。 最近Googl… →続きを読む
投稿者